Technical overview
The CommonsDB registry utilizes a federated architecture for managing and distributing rights information about public domain and openly licensed works.
It leverages the International Standard Content Code (ISCC) as a key to exchange rights information about digital assets. This design enables any third party or system with access to a copy of the file to retrieve rights information using the ISCC code derived from the digital media file.
The prototype registry serves as an open and accessible repository for ISCC codes, rights information and other metadata, and verifiable credentials from Data Suppliers, acting as a hub for rights information about public domain and openly licensed digital assets.
Core infrastructure
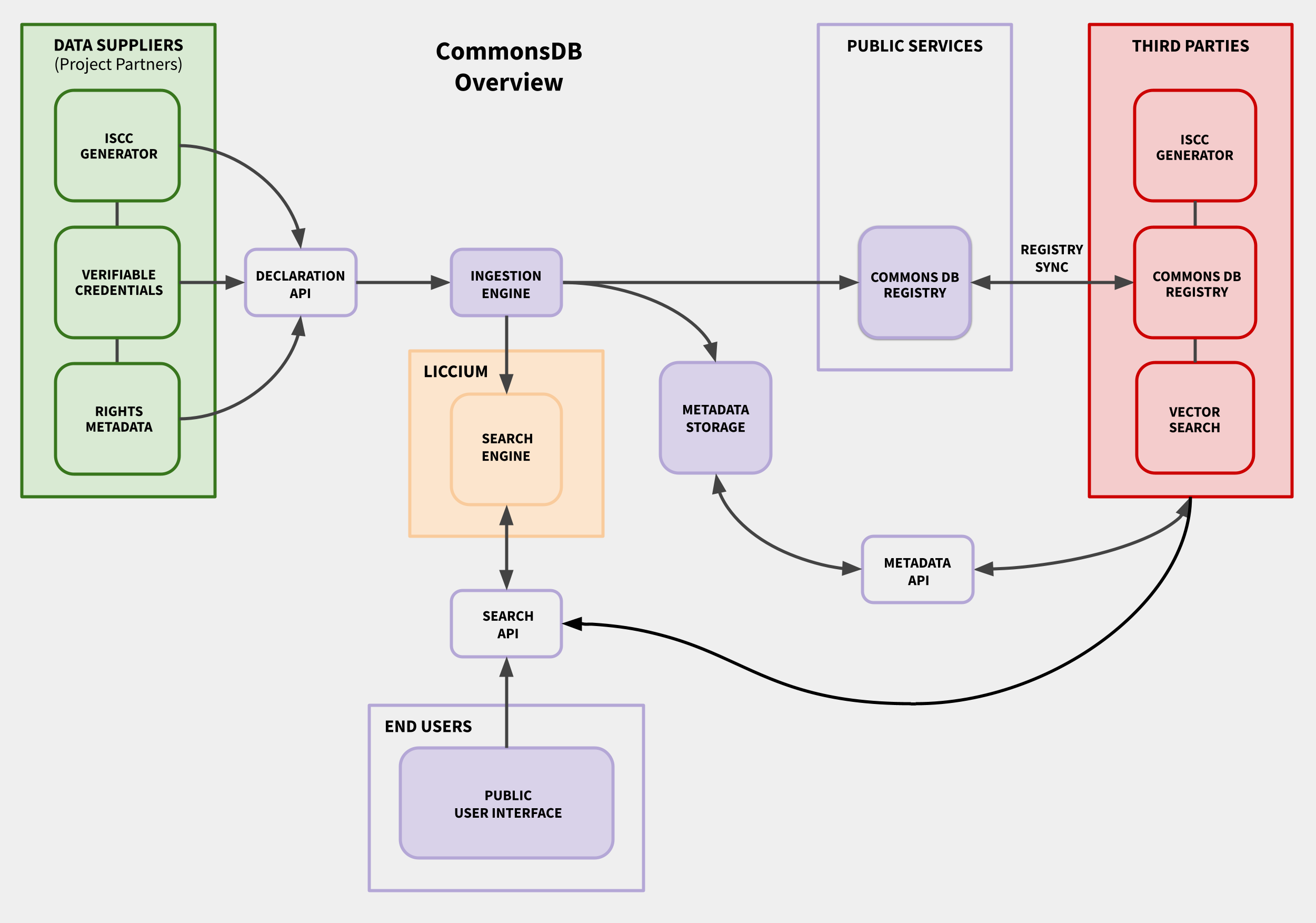
The CommonsDB core infrastructure includes the following elements:
- CommonsDB Registry: A registry of public domain and openly licensed digital assets, containing a subset of machine-readable declaration metadata from Data Suppliers. Designed for automatic and highly scalable retrieval and access by machines or platforms.
- Declaration API: The API through which Data Suppliers submit digitally signed metadata, such as ISCCs, Rights Metadata, and Verifiable Credentials, when making declarations to the registry.
- Ingestion Engine: Processes and integrates declarations data from Data Suppliers. Its inputs include digitally signed data objects with ISCCs, rights statements, certificates or Verifiable Credentials. The Ingestion Engine writes a subset of declaration metadata into the CommonsDB Registry.
- ISCC Generator: Outputs International Standard Content Codes (ISCC) and technical metadata for content identification and tracking. The software is installed locally by Data Suppliers and Third Parties, and provided as a service for the Public User Interface.
- Metadata API: Provides programmatic access to the Metadata Storage for the purpose of third-party integrations.
- Metadata Storage: Stores full declaration metadata and content-related information from Data Suppliers for search and discoverability. It will output metadata objects based on calls of the Metadata API by Third Parties or platforms.
- Public User Interface: Enables End Users to interact with the registry. End Users can query content, retrieve metadata, and upload media assets for search and verification.
- Search API: Enables Third Parties and the Public User Interface to query the metadata.
- Search Engine: Indexes metadata to power search functionality to Third Parties and the Public User Interface.
- Vector Search: Enables querying for identical or similar ISCC codes using vector-based comparison.
Process flows
The CommonsDB system operates through two main processes: the declaration of rights information and the search/verification of this information. The system is structured around three primary interacting parties: Data Suppliers, End Users, and Third Parties.
Data Suppliers interact with CommonsDB through the Declaration API that facilitates the structured submission of their data. Each declaration includes the following three elements:
- Content-Derived Identifier (ISCC): Data Suppliers generate ISCC codes locally within their technical infrastructure to create unique identifiers deterministically derived directly from their digital content.
- Rights Metadata: Data Suppliers provide rights metadata containing information about public domain and openly licensed digital assets, including a registry-supported rights statement, and a source URL that provides a reference for the declared work. Data Suppliers can also include other useful metadata about the digital assets in their declarations, such as titles, descriptions, attributions and creation dates.
- Verifiable Credentials: Data Suppliers supply verifiable credentials with their declarations, ensuring data integrity and proper attribution. To ensure the quality and integrity of the records, proper authentication of the source for each declaration is an important aspect. This is achieved by including publicly accessible verifiable credentials in the metadata records.
End Users access CommonsDB through CommonsDB Explorer, a public user interface which communicates with the system via the Search API. By uploading a media file, the system is able to generate its ISCC and retrieve any matching rights information stored in the registry.
Third Parties (such as repositories, UGC platforms and other types of data aggregators) can search and verify the rights status of digital content at scale by generating ISCC codes locally, implementing a local node of the CommonsDB Registry, and searching for exact or similar ISCC codes using a Vector Search (nearest neighbor search). The Search Engine enhances this search by enabling efficient querying of the indexed data, such as declaring party or rights status, by End Users and other Third Parties. Third Parties will be able to interact with CommonsDB via Registry Synchronization, ensuring data consistency across systems.